Hello, world
After all of the inspiring excitement of RStudio::conf 2018, I decided that I should start a blog. I’m not a statistician (I’ve never taken a formal statistics class, and for some unknown reason I confessed that to Charlotte Wickham at lunch during the conference, but she was very lovely about it, because she’s very lovely), and I’m not a computer scientist, but it is part of my day job to explain our team’s analysis methods to people who are also not statisticians or programmers - by and large, most of my presentations are to scientists who are experts in biology, immunology, virology, biochemistry…you get the idea.
My background is in physical chemistry, so many of these data science and/or machine learning concepts are new to me, too, and I find it helpful to consider analogies when I present these methods. The math is helpful (I now appreciate all of those statistical mechanics and quantum mechanics classes in graduate school), but sometimes a concrete, relatable example can help lay the foundation for complicated concepts. Some people can generate understanding through equations first, then apply to concrete examples; others go the other way, by breaking down an applied example first, then walking through the math. Also, depending on the nature of your work, you may not need more than a high-level overview of methods; in that case, there’s no need to delve into the guts of the algorithms.
What I’m going to try to do here is produce simple examples that can tackle some of those ideas. I’ll aim to link to more in-depth, potentially math-heavier explanations where I can, as well as to more tutorial-type example code and vignettes (I’d like to add my own code in the future, but…baby steps!). Most likely these examples will be gross oversimplications, but sufficient to get the idea across. If you have anything to add, please feel free to get in touch! The easiest way is to tweet me @lariebyrd - I haven’t gotten disqus working, yet (i.e., am confused).
Anyway, I figured I’d start with a common question: what is the difference between unsupervised and supervised learning?
Unsupervised vs. supervised learning
Unsupervised learning
So let’s start with this. With unsupervised learning, you’re typically trying to find structure in your data. Take this raw dataset, for example, where every data element is an emoji (no, the data set is not tidy):

Now, if I asked you to sort this into two bins, based on some criteria that you determine, what would you do?
*Jeopardy song*
(Just kidding, we’re stress-free here)
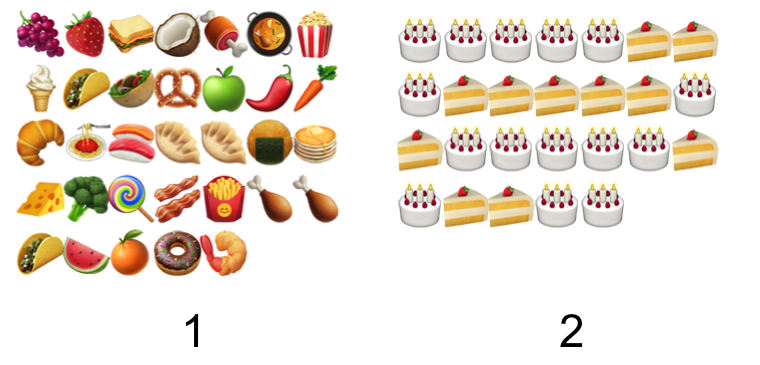
If you sorted them into NOT CAKE and CAKE, then:
We are definitely friends.
You just clustered the data!
Right, so now you probably have questions.
In real scenarios, how would you determine how many clusters there are? There are great tutorials and explanations for methods (this is a good one from UC Business Analytics), but good ‘ole trial and error or educated guessing can sometimes work, as well.
What if I chose some other criteria? Like, for example, savory vs. sweet? That’s legitimate, and a common problem with clustering and unsupervised methods. You may have a guess as to the underlying structure in the data, but there may be several possibilities, depending on the characteristics of the data.
Are pancakes cake? This is deep. I don’t know. And this is another issue you may face - the clusters you create will usually be exclusive (i.e., an item or observation can only belong to one or the other), but that doesn’t mean that the items won’t have qualities characteristic of both clusters.
Supervised learning
Now you have your clusters, or your classes. This is usually why, if you don’t have labeled data, you start with unsupervised learning and then move to supervised - the latter requires a training set for your algorithm (which can be the output of your clustering, as in this case). We’re tackling classification here - specifically binary classification, since we have two classes.
Based on our classes above (1. NOT CAKE, 2. CAKE), if I hand you a new set of raw data, can you sort them based on the criteria: IS IT CAKE?
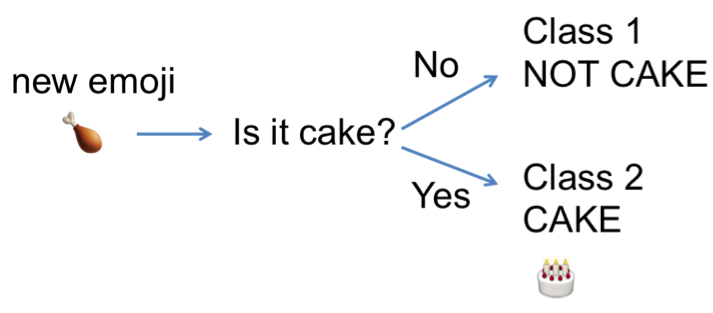
In this case, you’re going by image - is this image a cake, or not? If we broke that down, we’d be talking about some organization of pixels that make up this cake emoji. If you had actual food as your data, you’d be thinking: is this sweet? Is it fluffy? Does it have frosting? Likewise, if you were only given descriptors (text data): “moist” (sorry), “frosted,” “chocolate,” might help you sort that line of description into the “cake” pile, vs. descriptors like “spicy”, “crispy,” “salty” - that would (hopefully) be “not cake.”
So we’ve classified this element - it’s 1. NOT CAKE.
Your result will depend greatly on your training set; you can see, for example, if you had used a training set like this, instead:

This is an exaggerated example of an imbalanced set - it won’t be very good at distinguishing between classes 1 and 2, because it doesn’t have sufficient examples of 1. There are methods to address imbalanced sets.
It’s not imperative to cluster first and classify second - this is just a common pipeline if you don’t know what groupings exist in your data. It’s also possible to drill down further after utilizing a pipeline like this; for example, say you have separated out all of the cakes, and now you want to further separate WHOLE CAKES and CAKE SLICES. You could do that by creating a new, labeled training set:

And repeating.
Summary
With unsupervised learning, you typically only have input variables (x) - in this case, our emoji. Your goal is to find some underlying structure in the data - some way to start to group it, find patterns, meaningful relationships. Clustering is an example of this, and a common algorithm is k-means.
With supervised learning, you still have your input variables, x, but now you already also have the output y - that is, the label - the “correct answer.” And you want to see if you can train the algorithm to predict new y for new x - new labels for new observations. A common algorithm for classification is support vector machines.
The algorithms you choose will depend on the type of data you have, the computing resources available, and your personal preference. It will also matter if you are doing binary classification (distinguishing between two classes only), or have multiple classes. There are also other things to consider - parameter optimization, training and test sets, so on and so forth, but I promised a succinct, general example (and cake!), so hopefully this has been helpful to someone out there.
Further reading
Machine Learning for Humans
The most recent tasty cake I’ve made